Appearance
The Generated Code
When you save a QueryFirst .sql file (with the text "queryfirst" somewhere on the first line), QueryFirst will test-run the query, then run the configured generators. By default, this will mean the C# generator, that will generate (or regenerate) the [MyQuery].sql.cs file, directly in the folder containing the query. This file should appear nested underneath the query. For .net framework projects, this nesting is implemented in a template wizard. You must create your queries from the template to get nesting.
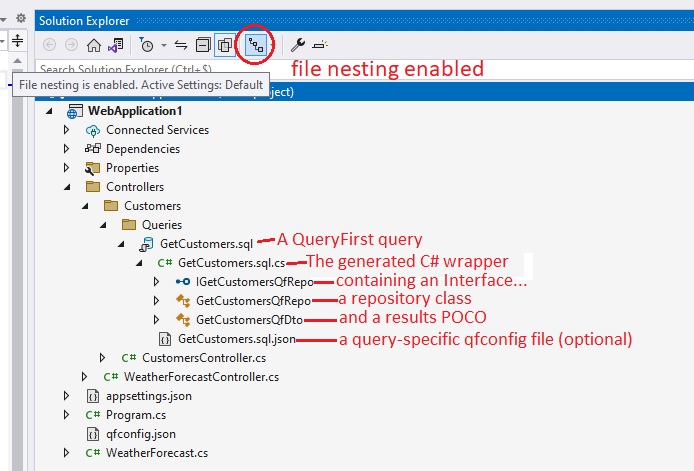
Solution Explorer with a QueryFirst query
For .net core, the nesting happens directly on the basis of filename. You may need to click the nesting button in the toolbar on top of the Solution Explorer, and select the Web settings for file nesting. You can create your queries just by creating a .sql file, and putting "queryfirst" somewhere on the first line.The generated code has 3 elements: an interface, a repository class with Execute() methods, and a POCO encapsulating a line of results.
The Interface
The interface, named I[MyQuery]QfRepo, is useful for dependency injection and for unit testing your calling code. If you're not already using a DI container, use poor man's DI. Your app code attacks the generated interface. In your test code, you can simply implement the interface. The editor generates your method stubs and you can instantiate and return some pocos.
The Execute methods
ADO provides 3 ways of executing a query: Execute, ExecuteScalar() and ExecuteNonQuery(). QueryFirst adds a fourth: GetOne(). If your query returns no results, you will only see ExecuteNonQuery(). If your query uses output parameters, you won't see GetOne().
Overloads for managing connection/transaction
For each of the four Execute() methods, the repository exposes the base method, taking just the input params, and an overload taking the input params, a connection and, optionally, a transaction. Now we have 8 execute methods.
Should I use the connection/transaction overloads?
The two common reasons for managing the connection yourself are as follows:
- You anticipate enormous result sets, and you want to iterate through your results without bringing the whole set into memory. The simple Execute() methods will materialise the full result-set as an in-memory List. Most of the time, this is no problem. The connection/transaction overloads will return an IEnumerable, on which you can call Yield(), to advance through your results without ever having them all in memory. You will need to take care to keep the connection open while you finish iterating.
- You want to manage raw transactions in your application code. Bear in mind you also have TransactionScope. This offers a simplified syntax for managing transactions. Nothing needs to be passed to the repositories, and you can keep using the simple Execute() methods.
Performance is generally not a good reason for managing the connection. Connection pooling means there is practically no cost to opening and closing a DB connection. Most times then, just use the connection-free overloads, and TransactionScope if you need it.
Async
By default, async methods are not generated. You can change this by putting the following in a qfconfig file...
json
"generators": [
{
"name": "CSharp",
"options": { "generateAsync": true }
}
]
You can change this option globally, in the qfconfig.json of your QueryFirst installation. For me, this is C:\Users\[MyUser]\AppData\Local\Microsoft\VisualStudio\17.0_33b107ce\Extensions\5ecopb0w.k0k\qfconfig.json. Since you're already using Everything, finding your installation qfconfig.json will be a snip.
You can set it for a project, in your project's qfconfig.json. You can turn it on for a specific query by putting it in the query's config file, [MyQuery].sql.json file (which you will likely need to create). Mads Kristensen's Add New File extension is a great way to quickly create config files (and .sql files, why not).
Once set, you will see 8 ExecuteAsync() methods matching the 8 existing ones.
Static
QueryFirst now exposes static Execute() methods. To use these, make sure you have assigned an instance of your QueryFirstConnectionFactory subclass to the static Instance property of the superclass, as described here. If you set the async option, you will also get static async execute methods.
Should I use the static methods?
If you're not using DI, and you don't intend to unit-test the calling code, there is no reason to instantiate your repositories. Static is perfectly fine. If you are using DI and unit-testing, you will greatly appreciate being able to mock or right-click-implement the repository interface, letting you use fakes for your testing.
Hooks for extending
QueryFirst repositories are intentionally left wide open for extending. The class definitions are marked partial, so you can directly add methods to the class in another file. You can also do lots of things by subclassing the repositories. In particular, the Create() and CreatePoco() methods are tagged as virtual, and the Poco results class has a virtual OnLoad() method that's called when the repository has finished assigning a row of results.